🕵️ The Counterfeit Conundrum: Can Code Language Models Grasp the Nuances of Their Incorrect Generations?

While language models are increasingly more proficient at code generation, they still frequently generate incorrect programs. Many of these programs are obviously wrong, but others are more subtle and pass weaker correctness checks such as being able to compile. In this work, we focus on these counterfeit samples: programs sampled from a language model that 1) have a high enough log-probability to be generated at a moderate temperature, 2) are incorrect, but 3) pass weak correctness checks.
Overall, we discover that open-source models have a very shallow understanding of counterfeits. First, models mistakenly classify them as correct. Second, they are worse at reasoning about the execution behaviour of counterfeits and often predict their execution results as if they were correct. Third, when asking models to fix counterfeits, the likelihood of a model successfully repairing a counterfeit is often even lower than that of sampling a correct program from scratch. Many self-repair and self-verification mechanisms rely on models being able to understand their counterfeit samples. In light of our findings, we recommend that care and caution be taken when employing these mechamisms, especially when no external feedback is incorporated.
Caveat: this paper focuses on open-source models, primarily CL-34B and DS-I-33B. We also present limited results on GPT-3.5 and GPT-4 which suggest that GPT-3.5 behaves similarly to the open-source models while GPT-4 has a much better understanding of counterfeits. Nevertheless, we still find that GPT-4 still exhibits some of these misunderstandings.
We use three datasets: HumanEval, LeetCode, and ODEX. To generate counterfeit examples, we first sample programs from Code Llama (CL), DeepSeek-Coder Instruct (DS-I), and StarCoder (SC) at temperature 0.6. Of the incorrect programs, we design a dataset-specific filter to remove those that do not pass mild correctness criteria (which include being able to compile).
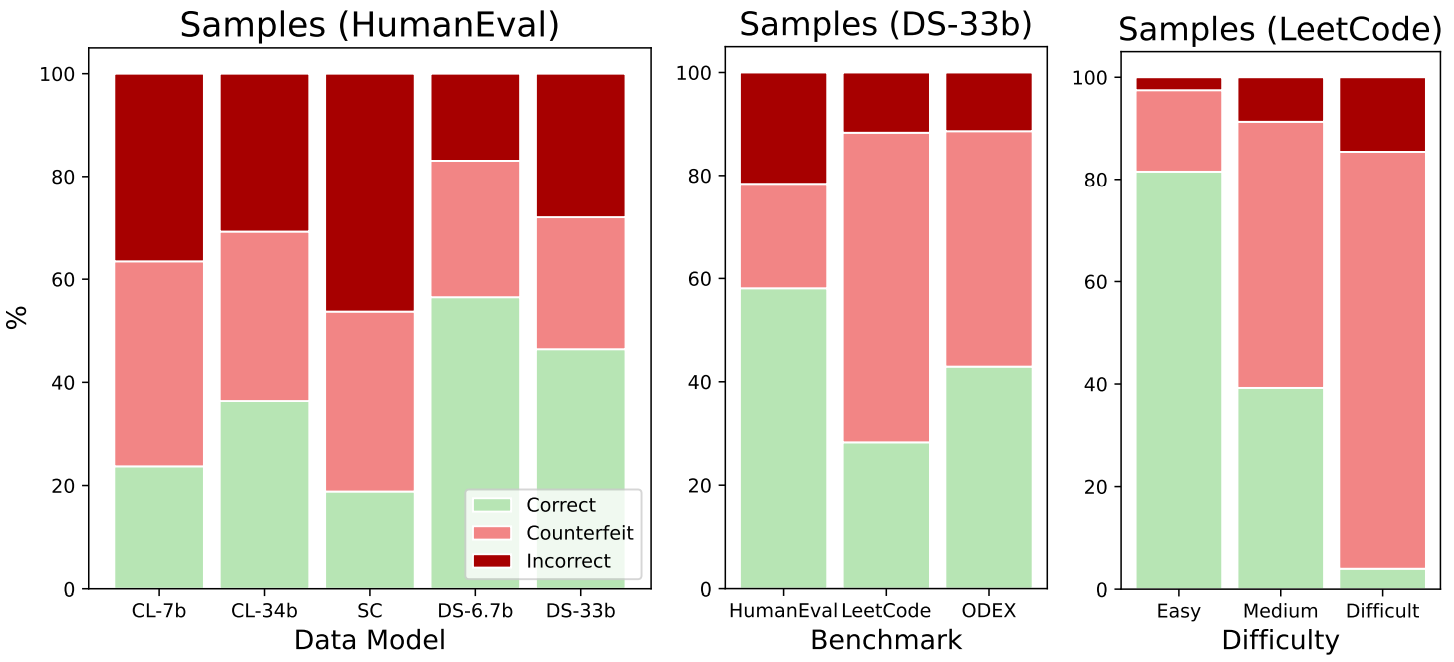
Below, we show the number of counterfeits generated by different models (left), benchmarks (middle), and problem difficulty levels (right), showing that counterfeits are widespread.
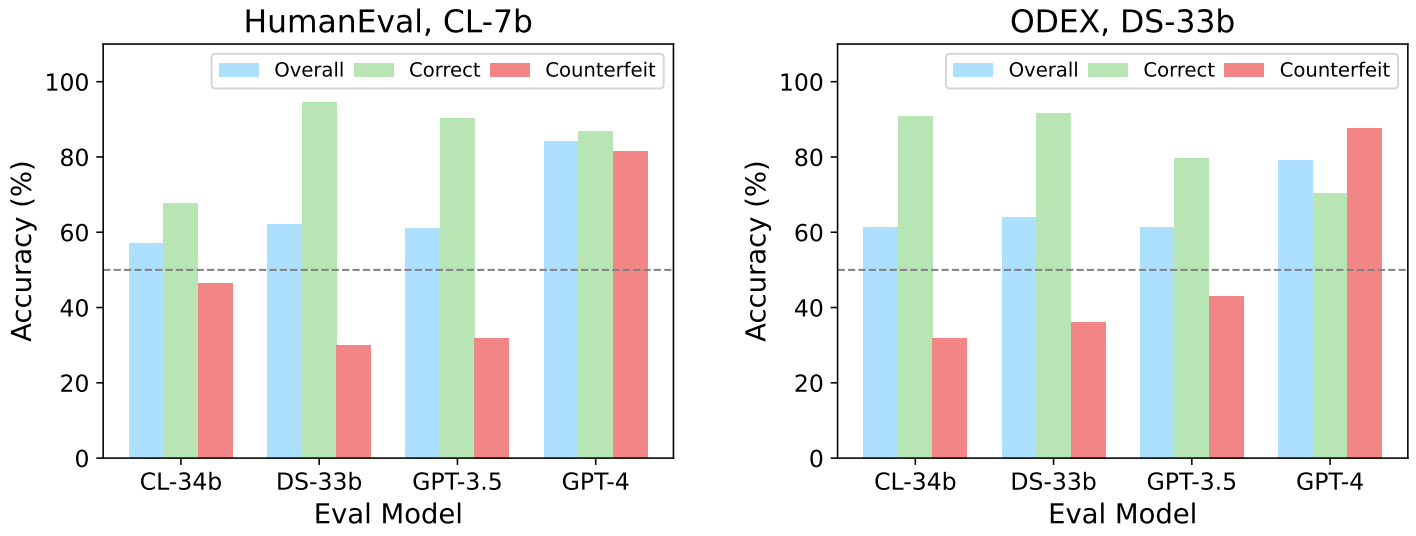
In the correctness checking task, the goal is to check whether a model-generated Python program (either correct or counterfeit) correctly implements a natural language (NL) specification on a balanced dataset.
In the results below, comparing the green and red bars shows that the classification performance of these three models on correct samples is much higher than their performance on counterfeit samples. Therefore, models are biased towards thinking counterfeit samples are correct.
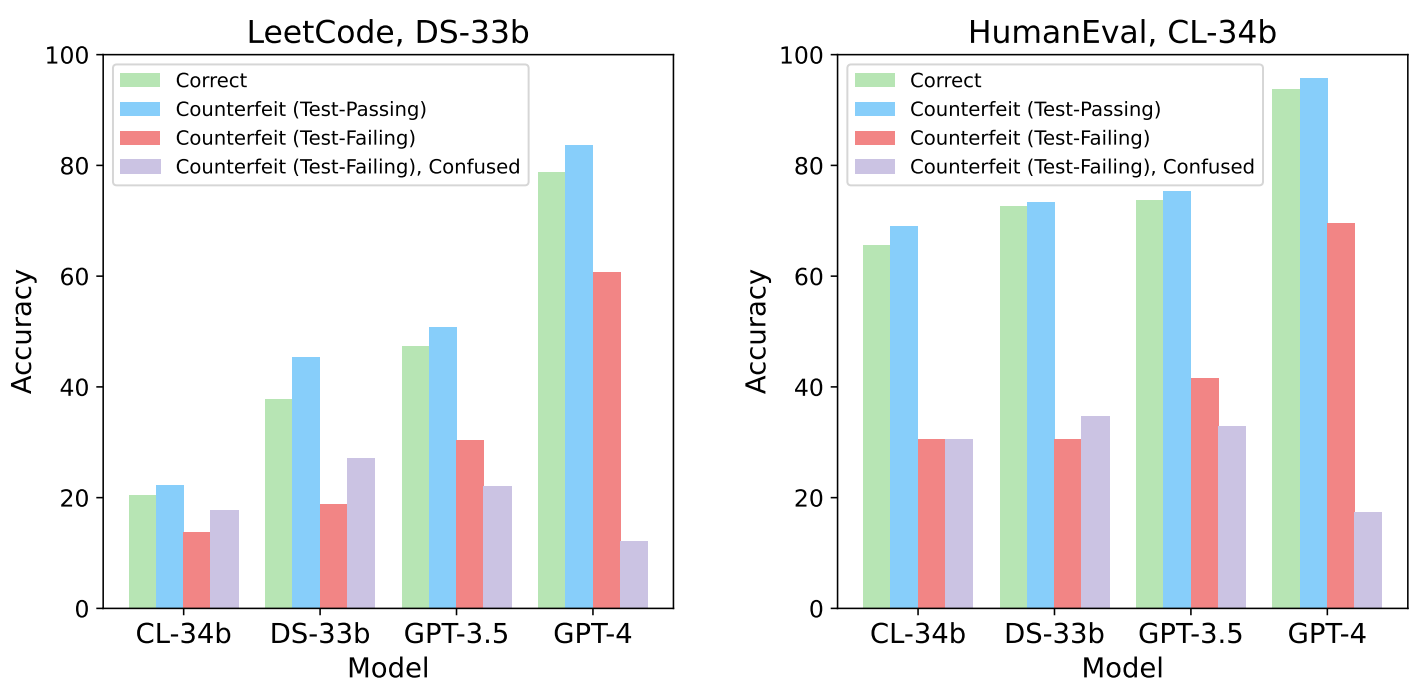
In the execution prediction task, the goal is to predict the execution output of a given model-generated Python program on a given test case. Each sample consists of a program P and an input I. Counterfeit programs can still pass tests, so we divide their execution samples into test-passing and test-failing samples. The accuracy of correct, test-passing counterfeits, and test-failing counterfeits are shown in green, blue, and red, respectively. In purple, we show the proportion of test-failing counterfeit samples where the model actually predicted the output of the correct program.
By comparing the green and blue bars with the red bar, we see that models fail much more at executing counterfeit programs when the semantics are incorrect. The purple bars provide further evidence of this: models other than GPT-4 frequently execute counterfeit programs as if they had the semantics of a correct program, sometimes even more often than their true semantics (red). As models only see the programs and not the problem statements, this suggests that they may be hallucinating the semantics of incorrect programs. Once again, we find that models have a difficult time distinguishing counterfeit programs from their correct counterparts, suggesting they may have a shallow understanding of program semantics.
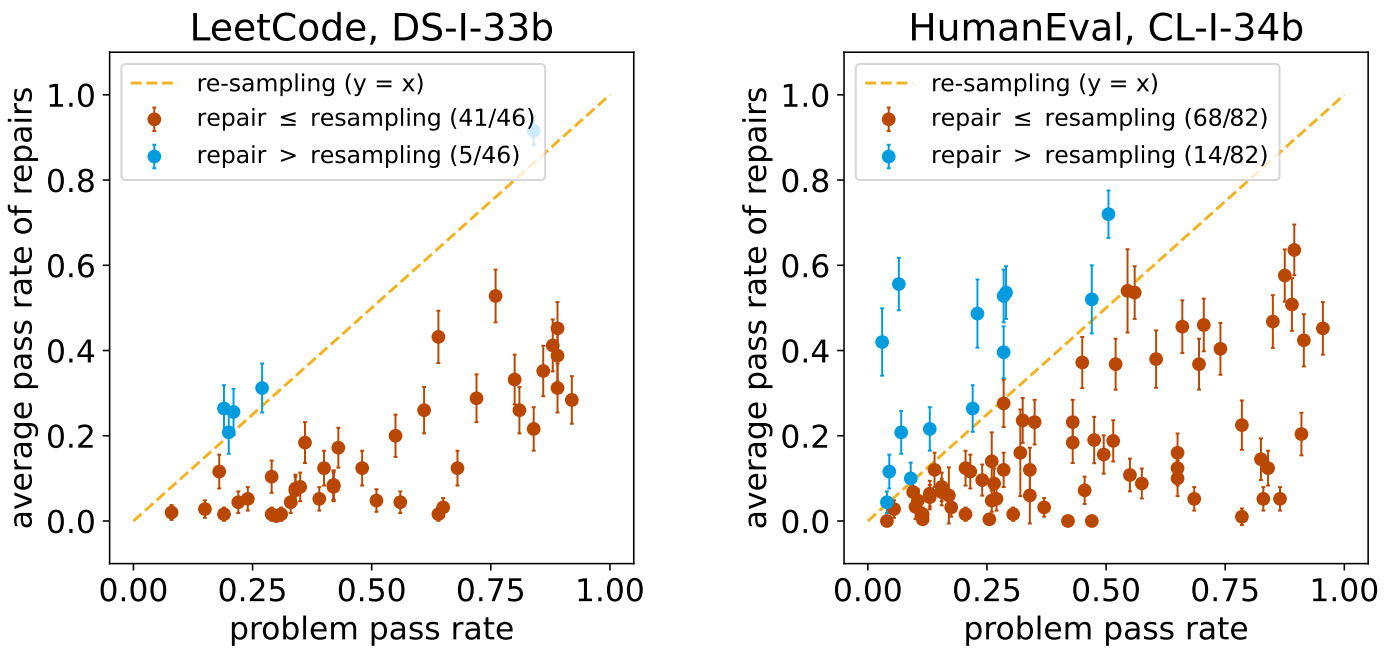
In the program repair task, the goal is to repair a given incorrect model-generated counterfeit program to correctly implement a given natural language specification. The model is not given any execution feedback other than the fact that the program is incorrect.
In the figures below, each point shows the mean success rate of repair for a particular problem. We compare against the naive baseline of resampling the model from scratch, corresponding to the y=x line. Most points fall under this line, suggesting that models cannot reliably repair counterfeit samples. This indicates that they could not understand why these counterfeits were deemed incorrect.
Is it easier for models to understand counterfeit samples from problems it finds easier? Intuitively, if a given programming problem is easy for a model to solve, we might believe models understand how to solve that problem and therefore better understand correct and counterfeit samples for that problem. To study this, we bucket problems into easy, medium, and hard via a model's pass@1 on that problem. We then calculate the average correctness checking, verification, and repair accuracy across each bucket.
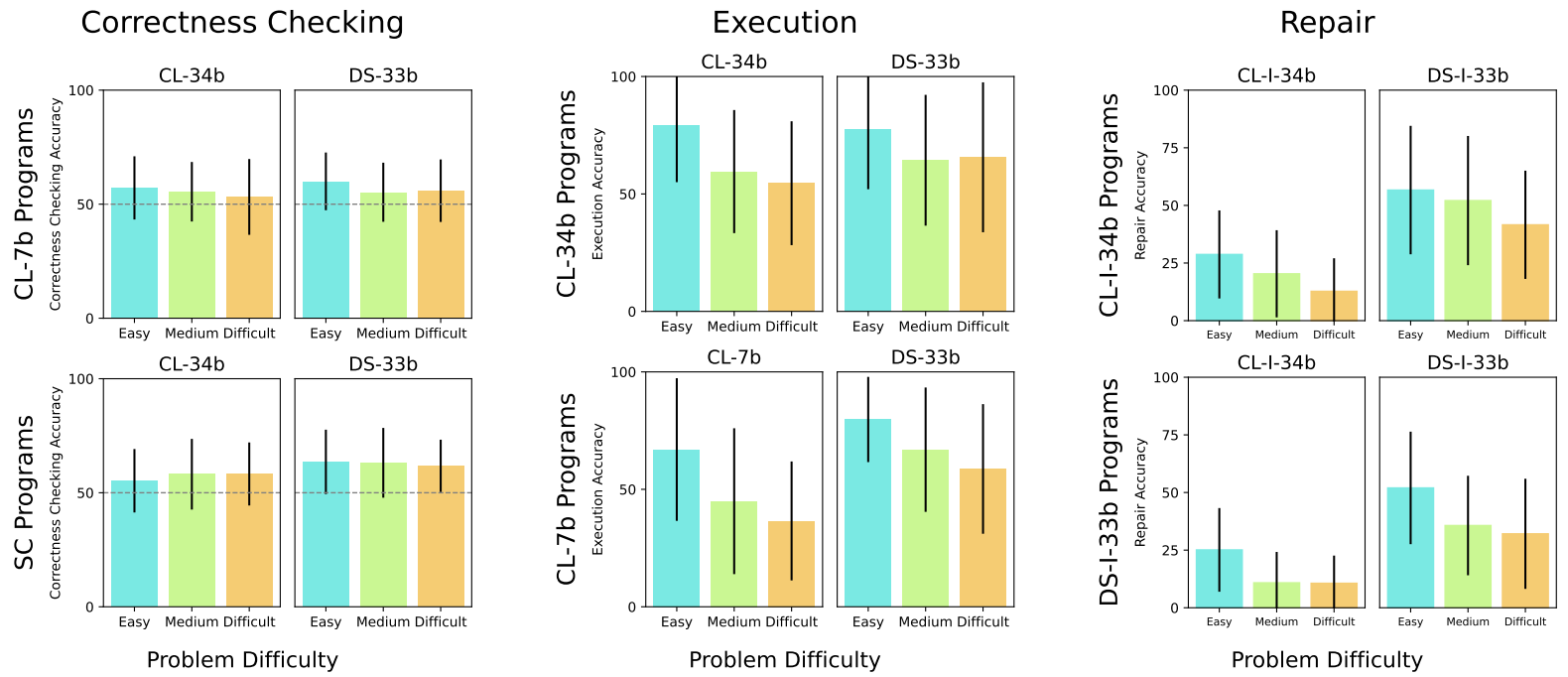
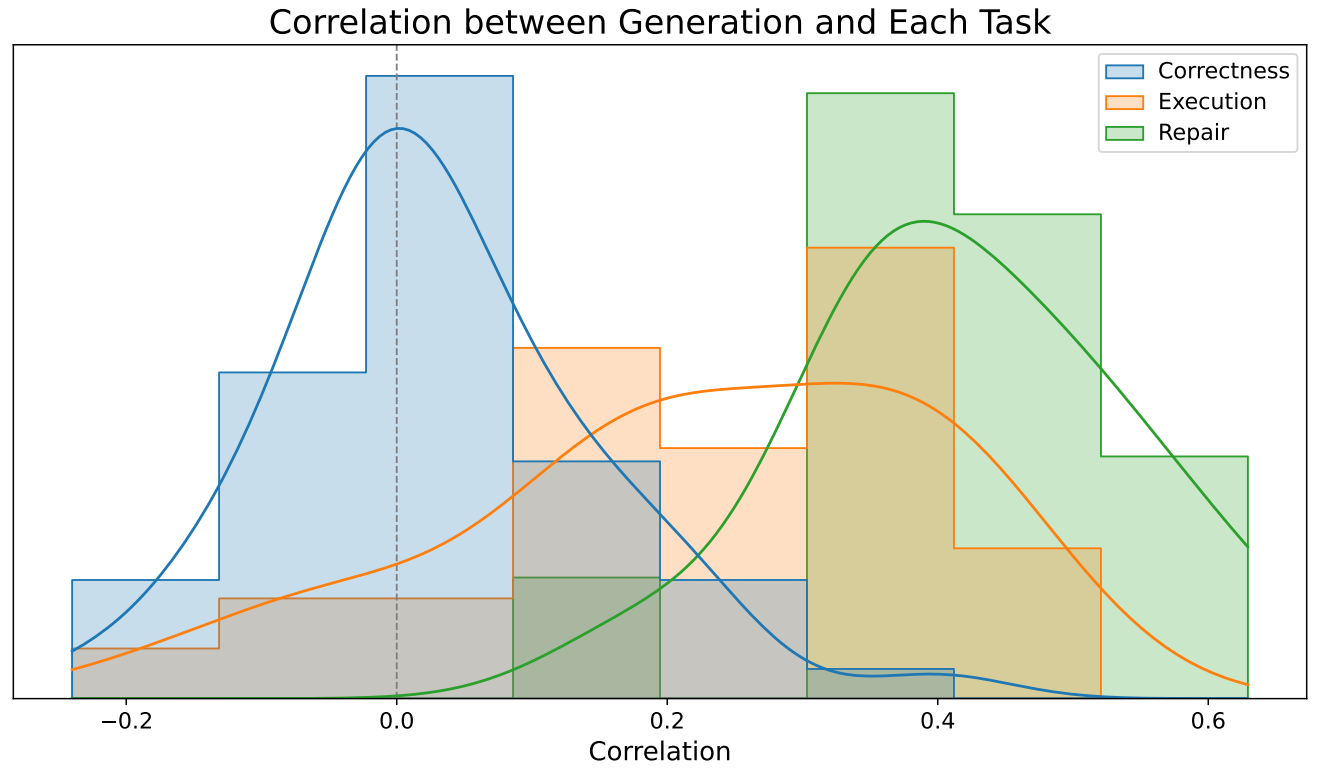
More precisely, the Pearson correlation between generation performance and each of the three tasks is shown below. Surprisingly, 1) correctness checking accuracies are relatively uncorrelated with problem difficulty, while 2) execution ability and the success rate of repair exhibit a modest amount of correlation with problem difficulty.
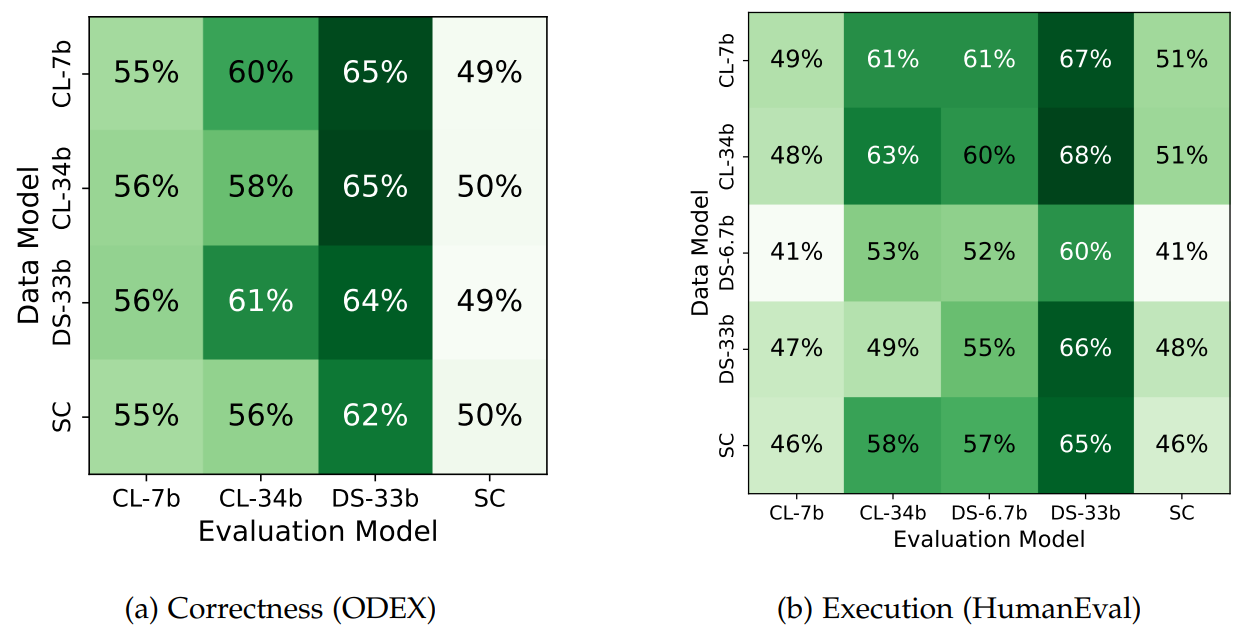
Do models perceive their own counterfeit samples differently? For a given model, its counterfeit samples had a high enough log-likelihood to be generated by the model, so one may hypothesize that models might have a harder time than other models at distinguishing their own counterfeit samples. However, we see below that for both correctness checking and execution prediction, the relative performance of different models is similar across datasets. Therefore, we find no evidence that models falter more on their own samples, suggesting that counterfeit samples may be general: those from one model are generally difficult for other models to understand as well.
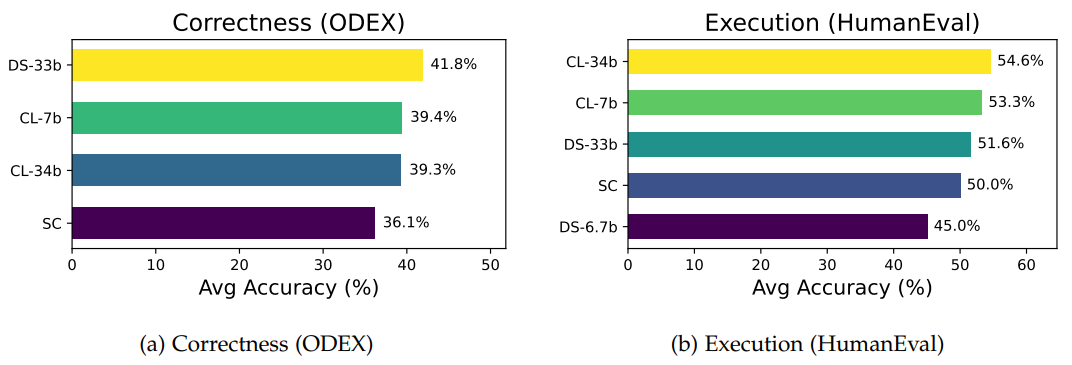
Do stronger models generate harder counterfeit samples? One might also believe that counterfeit samples of stronger models are harder to verify than those of weaker models, as stronger models are less likely to generate obvious mistakes. Below, we compare counterfeits generated by stronger (DS-33B, CL-34B) and weaker (CL-7B, SC) models. Since there does not seem to be a significant difference between the difficulties, models of all strengths can be used to generate counterfeit samples that are challenging for other models to understand.
In general, most counterfeit programs fall into one of three broad categories: (1) error in algorithmic design or implementation, (2) incorrectly understanding or completely ignoring details in the specification, (3) failing to address corner cases in the input space. We also discover three failure modes in correctness checking for the strongest model, GPT-4:
1) The model does not catch misunderstood or ignored details in the specification: Sometimes, the verification model doesn't catch important specification details that are misunderstood or ignored by the counterfeit sample.
2) The model fails to catch subtle implementation mistakes: Often, counterfeit samples follow a generally correct algorithm design but contain a subtle implementation mistake that models do not catch.
3) The model forgives an identified error: A third failure mode occurs when the model correctly reasons that the code is incorrect, but then makes up a justification for the error and judges the code as correct.
We bring attention to the counterfeit samples of a code language model: incorrect programs that a model thinks are correct and can pass surface-level correctness checks. In a sense, these counterfeit samples are adversarial to the model: models often cannot assess their correctness, reason about their execution, and struggle to repair them. Compared to other models, GPT-4 may be different from other evaluated models in this regard, in that they are much less susceptible to the traps we observe on counterfeit samples from other models.
While we operate in the domain of code, where it is simple to precisely check a model's understanding, we suspect that the same phenomena occur more generally in language models. Because models being able to understand their own counterfeit samples is a prerequisite to strong self-repair and self-verification schemes, we recommend that others be critical and careful in light of our findings.
@article{gu2024counterfeit,
title={The Counterfeit Conundrum: Can Code Language Models Grasp the Nuances of Their Incorrect Generations?},
author={Gu, Alex and Li, Wen-Ding and Jain, Naman and Olausson, Theo X and Lee, Celine and Sen, Koushik and Solar-Lezama, Armando},
journal={arXiv preprint arXiv:2402.19475},
year={2024}
}